Dr_Brown
Пользователь
Забрать можно из моей репы:
Мод позволяет брать из базы последние посты, заголовок, постер, описание, ссылку и постить в Ваш telegram канал.
Есть два режима работы:
1. Постинг релизов добавленых за последние 30 минут (настраивается по усмотрению, крон должен быть синхронизирован с интервалом установленным в переменной)
2. Рамдомно выбирает из базы, 10 постов, и постит в Telegram, по крон, интервал на Ваше усмотрение (внимание, это очень тяжелый запрос, не рекомендуется)
Системные требования:
1. Python 3.7 и выше
2. BeautifulSoup and PyMySQL libraries installed
3. Требуется битовое поле в таблице bb_bt_torents которое хранит 0 или 1, у меня оно назвывается pic_replase, можете назвать по своему.
Бота нужно создать в BotPhather, и добавить как админа, в ваш канал. Также требуется вписать ваш токен который вам выдаст BotPhather.
/*** Задача Cron запускается каждые 30 минут (режим 1) или интервал по пожеланию (режим 2) ***/
/usr/bin/python3 /home/main.py
файл main.py должен находиться в домашней папке или в любом удобном месте
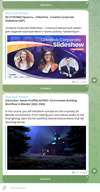
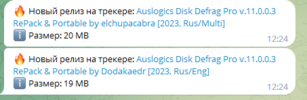
смотри комментарии в коде., пример на картинке
Примечание:
сильно хитрожопые оформления не берет.
Также не удалось взорвать imageban
Мод позволяет брать из базы последние посты, заголовок, постер, описание, ссылку и постить в Ваш telegram канал.
Есть два режима работы:
1. Постинг релизов добавленых за последние 30 минут (настраивается по усмотрению, крон должен быть синхронизирован с интервалом установленным в переменной)
2. Рамдомно выбирает из базы, 10 постов, и постит в Telegram, по крон, интервал на Ваше усмотрение (внимание, это очень тяжелый запрос, не рекомендуется)
Системные требования:
1. Python 3.7 и выше
2. BeautifulSoup and PyMySQL libraries installed
3. Требуется битовое поле в таблице bb_bt_torents которое хранит 0 или 1, у меня оно назвывается pic_replase, можете назвать по своему.
Бота нужно создать в BotPhather, и добавить как админа, в ваш канал. Также требуется вписать ваш токен который вам выдаст BotPhather.
/*** Задача Cron запускается каждые 30 минут (режим 1) или интервал по пожеланию (режим 2) ***/
/usr/bin/python3 /home/main.py
файл main.py должен находиться в домашней папке или в любом удобном месте
смотри комментарии в коде., пример на картинке
Примечание:
сильно хитрожопые оформления не берет.
Также не удалось взорвать imageban
")